ZFS replication and HA
Setup ZFS replication and High Availability in Proxmox VE. An entry-level approach. No NFS or Ceph shared storage will be used.


How to implement High Availability in Proxmox VE, on the cheep using ZFS replication and standard networking. No need for 40 G or 100 G networks. No need for a large pool of Enterprise grade SSD.
One of the many useful benefits of Proxmox (and other hypervisors) is the ability to provide High Availability for applications that don't have their own redundancy solution
Now, in a small cluster, that typically involves using central storage like a NAS, but the problem is, if the NAS goes offline so do your virtual machines.
You store your virtual machines on local storage and replicate them to the local storage of another server. But it's best to use an Enterprise grade SSD, you are going to write everything twice.
This is not intended for:
- 99.9999 HA applications, as they are a completely distinct and costly entity.
To accomplish this level, it is necessary to spend a large sum having a number followed by five zeros. - Routers or database servers, they have their own mechanisms for HA.
- DHCP and DNS server have their own mechanisms for replication of data.
We can mathematically define the availability as the ratio of (A), the total time a service is capable of being used during a given interval to (B), the length of the interval. It is normally expressed as a percentage of uptime in a given year.
| Availability % | Downtime per year |
|---|---|
99 | 3.65 days |
99.9 | 8.76 hours |
99.99 | 52.56 minutes |
99.999 | 5.26 minutes |
99.9999 | 31.5 seconds |
99.99999 | 3.15 seconds |
There are many ways to increase availability. The best way to do this is to rewrite your software so that you can run it on several computers at once. The software needs to be able to detect errors and do failover. This is easy if you only want to serve read-only web pages. But this is usually difficult and sometimes impossible because you can't change the software yourself.
The solution below can do a failover in minutes, without changing the software or using any fancy gear over normal networking (well, 1G may be slow).
What you need
What you need is a partition or a disk to use for just this purpose. Segregation of duties. On it, create a ZFS and call it something like localHA.
Set compression to lz4 and don't touch the ashift if you don't know what it will do, you may lose on performance, see the documentation. You can use a generic storage like local-zfs.
Replete on the other server. (you could use different name but KISS).
Setup Replication
The disk
You can do the setup from Datacenter, Node and VM level, use VM.
The default replication interval is every 15 minutes. Use the cron setting. Hourly Monday–Friday or anything else related to your use case of that VM and the speed and congestion of your network. Infrastructure and dashboards can have like daily, you do not change this too often.
- Target: the node to send the data to
- Schedule: determine how much date will be lost if a server goes down, unscheduled.
- Rate limit: is tricky to use, you need to know, ruffly, how long the replication takes and what is the interval, and that is tricky math.
- Comment: tell future you what this is good for
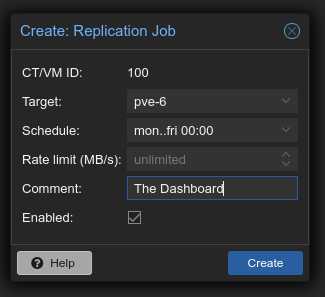
The backup cycle is also 24 h, why? It's because we will use HA. The traditional way is to recreate from a backup, but then you lose the first working hour. Now, even if the server is down when you start working, the system is usable. As your working hours are only 8 hours, you have the latest info from yesterday.
The real use case for this was a parts shop. The warehouse manager stayed later than the sales and prepared an inventory report.
It was crucial that the people could start ordering parts the first thing in the morning, before the store opened.
Other systems used the Monday to Friday, 7 – 18: Every 15 minutes rule
The HA Group
We want the VM to primarily run on PVE-6 and use PVE-4 as the backup in case of an emergency. Do not move the VM back.
Datacenter→HA→Groups click [Create] ID: on6group, tick nofailback and select servers pve-4 and give it priority 1 then add pve-6 with priority 10.
That is how our strategy will be implemented. Finally hit [Create]
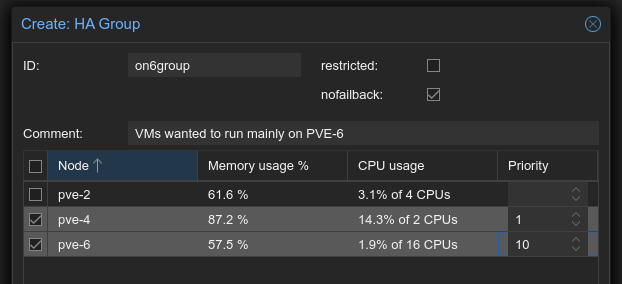
The CRM tries to run services on the node with the highest priority. If a node with higher priority comes online, the CRM migrates the service to that node. Enabling nofailback prevents that behavior. Why, sometimes nodes that trip unscheduled may have issues to restart, I prefer to oversee the process. With more server in the group, this isn't that necessary, but only if you do your testing right.
If pve-2 is AMD and the other Intel or some needed resources is missing, you need to keep the VM off it, or if you only have 2 servers and a Q-device.
The HA-Rule
For the magic to happen, we need a rule.
Datacenter→HA→Resources hit [Add] select the VM, select the Group, hit [Add]
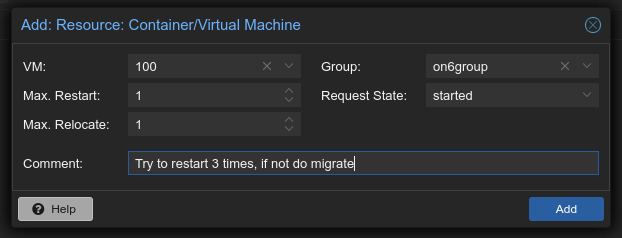
Occasionally a VM just randomly stops, usuallu a SW problem, for that reason you can use Max Restart: 3.
With 1 the migration starts quicker, that can also be a good thing.